Curve Fitting¶
Martin Vonk (2026)
It can be usefull to go from one soil model to the other. When the soil parameters are known the soil water retention curve and hydraulic conductivity function can be fitted.
[1]:
import matplotlib.pyplot as plt
import numpy as np
import pedon as pe
[2]:
def plot_compare(soilsample: pe.SoilSample, soilmodel: pe.SoilModel) -> None:
"""Plot the soil water retention curve (SWRC) and hydraulic conductivity function (HCF) for a given soil sample and fitted soil model."""
f, ax = plt.subplots(1, 2, sharey=True, figsize=(4.2, 4.5))
ax[0].scatter(soilsample.theta, soilsample.h, c="k", s=10, label="Soil Sample")
_ = pe.plot.swrc(
soilmodel, ax=ax[0], label=f"Fitted Soil Model {soilmodel.__class__.__name__}"
)
ax[0].set_yscale("log")
ax[0].set_xlim(0, 0.5)
ax[0].set_yticks(soilsample.h)
ax[0].set_xticks(np.linspace(0, 0.5, 6))
ax[1].scatter(soilsample.k, soilsample.h, c="k", s=10)
_ = pe.plot.hcf(soilmodel, ax=ax[1])
ax[1].set_yscale("log")
ax[1].set_xscale("log")
k_left = 10 ** (np.floor(np.log10(min(soilsample.k))) - 1)
k_right = 10 ** (np.ceil(np.log10(max(soilsample.k))) + 1)
ax[1].set_xlim(k_left, k_right)
ax[0].set_ylabel(r"|$\psi$| [cm]")
ax[0].set_xlabel(r"$\theta$ [-]")
ax[1].set_xlabel(r"$K_s$ [cm/d]")
ncol = 3
ax[0].legend(
loc=(-0.02, 1),
fontsize=6,
frameon=False,
ncol=ncol,
columnspacing=0.8,
handlelength=2.5,
)
f.align_xlabels()
# plt.close(f)
[3]:
sn = "Sand"
soil = pe.Soil(sn).from_name(pe.Genuchten, "HYDRUS")
soilm_genuchten = soil.model
soilm_genuchten
[3]:
Genuchten(k_s=np.float64(712.8), theta_r=np.float64(0.045), theta_s=np.float64(0.43), alpha=np.float64(0.145), n=np.float64(2.68), l=np.float64(0.5))
[4]:
h = np.logspace(-4, 6, num=11)
k = soilm_genuchten.k(h)
theta = soilm_genuchten.theta(h)
[5]:
soilsample = pe.SoilSample(h=h, k=k, theta=theta)
soilsample
[5]:
SoilSample(sand_p=None, silt_p=None, clay_p=None, rho=None, th33=None, th1500=None, om_p=None, m50=None, d10=None, d20=None)
[6]:
soilm_panday = soilsample.fit(pe.Panday)
soilm_panday
[6]:
Panday(k_s=np.float64(571.708265814981), alpha=np.float64(0.1461801617834131), beta=np.float64(2.652658840845942), brook=np.float64(3.7979374333607314), sr=np.float64(0.1045283561554307))
[7]:
plot_compare(soilsample, soilm_panday)
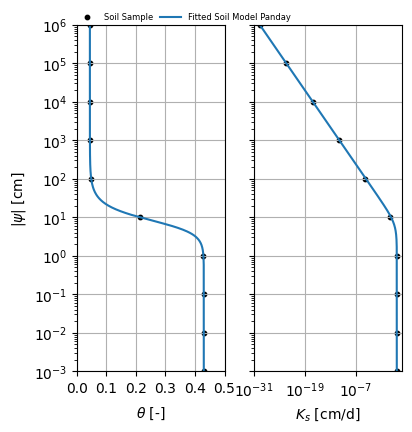
The fit method finds the optimal curve through both the soil water retention curve and hydraulic conductivity function at the same time using the least squares algorithm. All parameters are subject to the optimization algorithm.
The fit method uses the optimization algorithm from the 1991 RETC Code for Quantifying the Hydraulic Functions of Unsaturated Soils by M.Th. van Genuchten, F.J. Leij and S.R. Yates.
The objective function \(O(b)\) minimized is:
$ O(b) = \sum`^N\_{i=1}(w_i(:nbsphinx-math:theta`_{o,i}-\theta_i))^2 + \sumM_{i=N+1}(w_iW_1W_2(Y_{o,i}-Y_i))2$
Using the SciPy least-squares algorithm.
With \(N\) the number of \(\theta\) data points and \(M\) is the number of \(K\) and \(\theta\) data points
\(w_i\) are the individual weight factors per measurements (by default 1 for each measurement)
\(W_1\) is the weight factor for the hydraulic conductivity function with respect to the soil water retention (default is 0.1)
\(W_2\) is the proportional weight factor for two different data types and elimination factor for different units. By default the formulation for \(W_2 = \frac{(M-N)\sum^N_{i=1}w_i\theta_{o,i}}{N\sum^M_{i=N+1}w_i|Y_{o,i}|}\).
\(Y\) is indicates the for the logaritmic transform of such that \(Y = log_{10}K\).
It can be favorable to only optimize the relative hydraulic conductivity function, and leave parameter k_s untouched. That kan be achieved by providing k_s to the fit method.
[8]:
soilm_panday = soilsample.fit(pe.Panday, k_s=max(soilsample.k))
soilm_panday
[8]:
Panday(k_s=np.float64(712.7999894094452), alpha=np.float64(0.1465762339443846), beta=np.float64(2.643758801715091), brook=np.float64(3.8328536624960146), sr=np.float64(0.10448683155085352))
It is also possible to provide bounds for the parameter space. By default, the bounds argument is None which takes the stored parameter bounds per soil model:
[9]:
panday_bounds = pe.get_params("Panday")
panday_bounds
[9]:
| p_ini | p_min | p_max | |
|---|---|---|---|
| k_s | 50.00 | 0.00100 | 100000.0 |
| theta_r | 0.02 | 0.00001 | 0.2 |
| theta_s | 0.40 | 0.20000 | 0.5 |
| alpha | 0.02 | 0.00100 | 0.3 |
| beta | 2.30 | 1.00000 | 12.0 |
| brook | 10.00 | 1.00000 | 50.0 |
[10]:
panday_bounds.loc["k_s", "p_min"] = 650
panday_bounds.loc["k_s", "p_ini"] = max(soilsample.k)
soilm_panday = soilsample.fit(pe.Panday, pbounds=panday_bounds)
soilm_panday
[10]:
Panday(k_s=np.float64(650.0261621962741), alpha=np.float64(0.14641140248932677), beta=np.float64(2.6474459117538136), brook=np.float64(3.818288565387593), sr=np.float64(0.104504122679695))
Other available option are to print the optimization result.
[11]:
soilm_panday = soilsample.fit(pe.Panday, silent=False)
SciPy Optimization Result
message: `gtol` termination condition is satisfied.
success: True
status: 1
fun: [ 2.220e-05 2.220e-05 ... -8.042e-05 -2.758e-04]
x: [ 5.717e+02 4.495e-02 4.300e-01 1.462e-01 2.653e+00
3.798e+00]
cost: 5.55697272894851e-07
jac: [[ 0.000e+00 9.167e-12 ... 1.728e-12 0.000e+00]
[ 0.000e+00 5.042e-11 ... 1.382e-10 0.000e+00]
...
[ 1.946e-06 0.000e+00 ... -4.053e-02 -1.764e-02]
[ 1.946e-06 0.000e+00 ... -5.026e-02 -2.187e-02]]
grad: [ 1.618e-14 3.304e-09 -3.684e-10 5.778e-09 1.076e-09
5.678e-11]
optimality: 1.7779544758553858e-09
active_mask: [0 0 0 0 0 0]
nfev: 10
njev: 10
To parse other parameters for W1, W2, and individual weights there are other keyword arguements that for the fit method.